0x00.Before we start
CVE-2016-5195, also known as the dirtyCow, is a famous race-condition bug in Linux Kernel. It allows hackers to make an privileged overwrite on files that can only be read by them.
Before we start, let’s take a look at some antecedent knowledge.
1. Copy-on-Write
Before learning about what is dirtyCow, we need to know “what is a COW“ firstly. Let’s just start from some legacy knowledge.
basic COW
COW, also the Copy On Write , is a mechanism to reduce the cost of system resources. A complete copy of a process’s whole content of its address space won’t be allocated to its new child process while the process trying to make a new child process by the fork() syscall, but a less expensive way is chosen:
- The parent process and the child process will share the same page frames instead of allocating new page frames to the child and make a copy.
- The allocation will happen only when one of them is trying to write new data on it, then comes the time of copying.
- All page frames will be read only right after the
fork(), so the kernel can make the detection of writing by the page fault and start the COW.
mmap & /proc/self/mem & COW
Similarily, COW also happen in the process of making a write on /proc/self/mem which representing the whole virtual memory address space of current process in Linux. If we make a mmap() of a read-only file and try to overwrite it across the /proc/self/mem, the COW will also happen and a copy of corresponding content of the fill will be make, thus the original file will not be affected.
2. page fault
The Memory Management Unit (aka MMU) is used to translate virtual address to physical address. But it’s possible that there’s no a valid PTE(page table entry) for a memory access on a specific address currently, which means that the process tried to access a page without proper preparations. So a hardware interrupt called page fault will be raised.
Though it’s name is “fault”, but it may not really mean that a trouble occurs, it just indicates that “something is wrong”.
Page fault may happen while:
- When we’re trying to access a page that’s not in the physical memory.
- When we’re trying to access a page that we don’t have permission to do so.
To subdivide, there’re three kinds of page fault:
When we’re accessing a valid address:
- There’s no corresponding page frame in the memory. Then the corresponding content will be read from the disk to the memory, and the MMU will make the mapping. This is hard page fault.
- The page is already in the memory, but the mapping hadn’t been established. Then the mapping will be made(e.g. shared memory). This is soft page fault.
When we’re accessing an invalid address:
- The page is not in the process’s address space. Then the process will be killed by SIGSEGV. This is invalid page fault.
Handle the page fault in Linux kernel
Now we’re going to analyze the code of page fault handler in Linux kernel v4.4, which has the dirtyCOW in it : )
We mainly focus on the situation of using /proc/self/mem to write on the read-only file’s mapping memory, which causes the copy-on-write and the vulnerability.
By the way, we can read the source code of Linux kernel online on https://elixir.bootlin.com/.
For general page fault handling, no matter the entry is __do_page_faulr() or faultin_page(), they’ll all call the handle_mm_fault() and the control flow is as below:
1 | handle_mm_fault() // allocate the PTE |
① handle_pte_fault(): handle page fault according to the PTE
The function is defined in mm/memory.c , which is used to handle the page fault according to the PTE.
1 | /* |
FIrstly it’ll check whether the page is present(e.g. for x86, the PTE has a PTE_P bit that indicates whether the page is present), if so, it means that we may need to allocate a new page frame or swap the old page back:
1 | { |
If the page is already in the main memory, check whether the _PAGE_PROTNONE is set. if so, then it comes to the do_numa_page() path.
If not, then it’ll check whether the FAULT_FLAG_WRITE is set. If so, it’ll check whether we have the permission to write. If not, then it comes to the time of COW!
1 | //... |
② do_fault(): call specific function according to the kind of fault
This function is also in mm/memory.c , it’ll call specific function according to the kind of fault.
1 | /* |
③ do_cow_fault(): make the basic paging
The function is also located in mm/memory.c . It’ll allocate the page and called the __do_fault() to deal with the fault, which moves corresponding data to the page. Then the PTE of the page fault address in the page table will be set to the new page.
1 | static int do_cow_fault(struct mm_struct *mm, struct vm_area_struct *vma, |
The core of __do_fault() is just to call the specific function of a vm_area’s operation table.
1 | /* |
The do_cow_fault() does make the basic paging, but the operation of writing new data hadn’t been done yet. So let’s come to the final step now.
④ do_wp_page(): make the copy-on-write
When the page is in the memory but we don’t have the permission to write on it, the do_wp_page() will do the copy-on-write to make a copy of the original page, and out writing will only affect this individual new page frame.
1 | /* |
Firstly it’ll check whether it’s a special mapping page. If so, it’ll check whether the vm_area has the VM_WRITE|VM_SHARED flags, which means that it’s a shared and writable memory region and we only need to make the page writable. If not, then the wp_page_copy() will be called to do the COW.
1 | struct page *old_page; |
For normal page, if it’s an anonymous page(not related to a file, e.g. stack and heap), then check for the mapping times, if it’s 1, just mark the page writable is okay.
1 | /* |
After all conditions above are eliminated, it comes the time to do the copy-on-write. We allocate a new page there and copy the content from the old page across wp_page_copy().
1 | /* |
3. COW while writing to /proc/self/mem
So when we use mmap() to map a read-only file, and use the /proc/self/mem to write directly on the mmap area, the control flow is as below:
SYSCALL: writeのflow
Syscall write() will called the sys_write() in kernel, which defined in fs/read_write.c :
1 | SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf, |
This function will finally call the specific write() function of the file struct’s file_operations table.
1 | entry_SYSCALL_64() |
For /proc/self/mem, it will be the mem_write(), and the core of this function is mem_rw() in fact, which defined in fs/proc/base.c . It’ll allocate a temporary page to copy the data, and do the real operation by access_remote_vm().
1 | static ssize_t mem_rw(struct file *file, char __user *buf, |
mem_rw() is a function that consists of operation of both reading and writing. The core of read/write operation is in access_remote_vm() , and it’ll call __access_remote_vm() defined in mm/memory.c :
1 | /* |
It’s core is using a loop to copy the data page by page. Firstly it’ll try to get the destination page’s page struct by get_user_pages(). If it failed to get the page, it’ll find out the vma that the target address belongs and call the vma->vm_ops->access() to hande it.
1 | while (len) { |
If it successfully gets the page struct, it’ll use kmap() to map the page to a writable virtual address space temporarily in highmem area so that we can read/write the page frame by it’s virtual address that we just mapped. Then it comes to the real read/write time.
1 | } else { |
So let’s look at how it get the page by get_user_pages() now. It’ll finally call the __get_user_pages_locked() and the __get_user_pages() will be called, which defined in mm/gup.c. It mainly use a big loop to handle everything:
1 | long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm, |
We mainly focus on the core in this loop. It’ll firstly use the follow_page_mask() to get thepage struct of target virtual address. If it failed, it means that we cannot access the page frame right now. There’re two reasons for this:
- There’s no a physical page frame for this virtual address.
- We don’t have the permission to access the page now.(e.g. we’re trying to write an unwritable page)
For this condition, which presents a “page fault”, the program will call the faultin_page() to handle this.
1 | //... |
For copy-on-write, it’ll be like this:
When we tried to access a page firstly, there’s no physical page frame for it (lazy kernel will only create the
vm_area_structat the beginning, the page will be allocated only when it’s accessed), so thefollow_page_mask()returns a NULL, representing a page fault. Then the program will usefaultin_page()to handle it and the physical page frame will be allocated.Then it’ll be back to the tag
retryand recall thefollow_page_mask(). If we’re trying to write on an unwritable page, thefollow_page_mask()will return a NULL again, representing a page fault. Then the program will usefaultin_page()to do the copy-on-write.
/proc/self/mem represents the whole memory of a process, and it’s always writable for the process. So it won’t make the SIGSEGV while writing on a read-only mapped page, but the copy-on-write will be done.
So the whole chain is as below:
1 | mem_rw() |
Then let’s have a look at the faultin_page() .
First time of page fault
When we tried to access a page firstly, there’s no physical page frame for it (lazy kernel will only create the vm_area_struct at the beginning, the page will be allocated only when it’s accessed), so the follow_page_mask() returns a NULL, representing a page fault. Then the program will use faultin_page() to handle it, which defined in mm/gup.c :
1 | static int faultin_page(struct task_struct *tsk, struct vm_area_struct *vma, |
It finally call the handle_mm_fault() to handle the page fault as below:
1 | faultin_page() |
Notice that at the final stage it’ll check for VM_FAULT_WRITE flag and clear the FOLL_WRITE bit in the caller’s flag filed. For allocating a writable page, the flag bit will be clear. But for a read-only page’s allocation, this stage will be ignored.
Second time of page fault
Though we’d like to write on a read-only mapped page across the /proc/self/mem, the page fault handler do it in the traditional way, so the page is read-only for us yet, and the follow_page_mask() will return NULL again, representing a page fault.
So we will enter the faultin_page() again and do the copy-on-write. This time the kernel will allocate a new page for us to write, and the FOLL_WRITE bit of variable foll_flags in __get_user_pages() will be cleared in faultin_page() ‘s final stage.
The call chain is as below:
1 | faultin_page() |
After twice page fault, we’re back to the tag retry in __get_user_pages() and try to get the page for the third time. Now the FOLL_WRITE bit is cleared, which means that the kernel will treat it as a writable page for us. So the follow_page_mask() will get the page successfully finally.
0x01. Analysis of the vulnerability
Now let’s have a review of the whole process of writing to a read-only mapped file by the /proc/self/mem.
race condition under multi-thread environment
We can notice that the follow_page_mask() check for whether the page will be written by the FOLL_WRITE bit of foll_flags , but the operation of writing is decided by the write param passed to mem_rw() . So there’s a subtle race condition there. Now let’s start two threads to make it:
- Thread[1]: Write the data to read-only mmapped file across the
/proc/self/memrepeatedly. It’ll cause the copy-on-write. - Thread[2]: Use
madvise()syscall to tell the kernel to mark the memory area of read-only mmapped file unused repeatedly. Then the page frame of this area will be released and the PTE will be cleared.
Then it comes to the interesting part:
Four times of getting pages & Three times of page fault
We can easily notice that there’s a race condition like this:
- Thread[1] finished twice page fault, prepared to get the page for the third time.
- Thread[2] used the
madvise()syscall to clear the page. - Thread[1] failed to get the page for the third time, “page fault” again.
Now the page mapped to the file will be back again just like how the first time of page fault was handled. So the program will try to get the page for the fourth time. Notice that the FOLL_WRITE bit is cleared, the kernel will think that “we’re going to read this page”. So we can get the page “normally”.
But backing to the mem_rw(), we’re trying to write the page in fact. So the file mapping page will be written directly. Then we have completed a privileged overwrite on a read-only file.
0x02. Exploit
So we know that how dirtyCOW works now: just use two threads to make a race condition.
- Thread[1]: Write the data to read-only mmapped file across the
/proc/self/memrepeatedly. - Thread[2]: Use
madvise()syscall to tell the kernel to mark the memory area of read-only mmapped file unused repeatedly.
poc
1 | /** |
We can see that we successfully overwrite a read-only file with our poc.
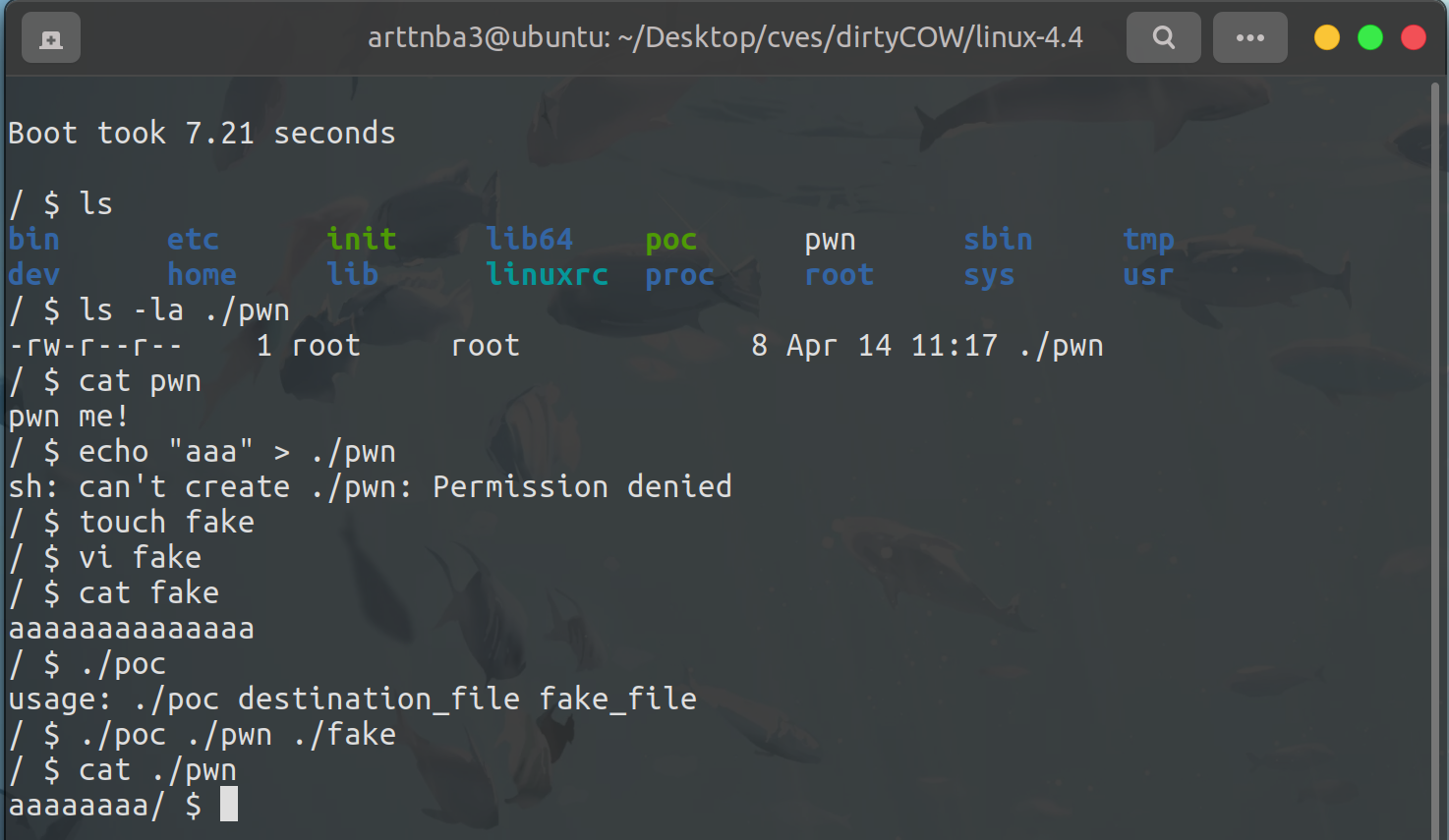
Privilege Escalating
一、add a new root-privileged user
We can modified the /etc/passwd and add a new user with root privilege. And the root comes with our login.
1 | /** |
Don’t forget to compile with param -lcrypt .
1 | gcc dirty.c -o dirty -static -lpthread -lcrypt |
Run it, and we can get the root.
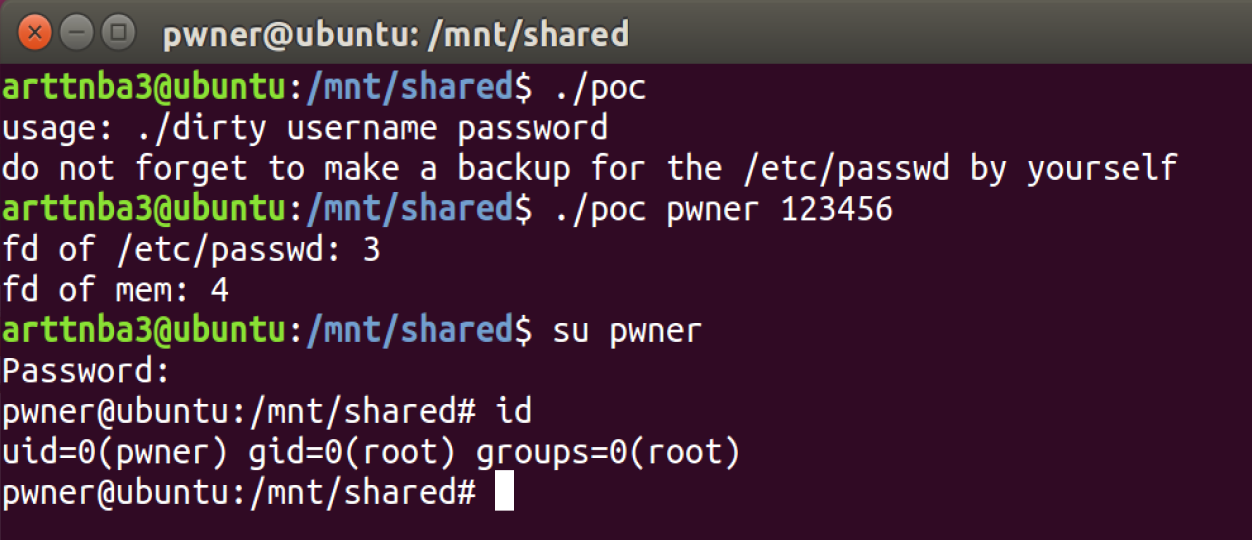
二、privileged by SUID
We can also overwrite some SUID programs(which will be run with the uid set in advance) to malicious code to archive the privilege escalating. I choose to overwrite /usr/bin/passwdthere.
I used the
msfvenomto construct the payload as below:
1 | /** |
Run it, and we can get the root.