「さらば、全てのリヌクス カーネル エクスプロイテーション。」
0x00. Before we start
It may be my last time to design the Pwn challenge for D^3CTF before my undergraduate graduation. Although I have always wanted to come up with some good challenges, I have been too inexperienced to create anything particularly outstanding. I hope that this time I can bring you with something special : )
The challenge comes from the question that I’m always thinking about:
- As a hacker, how extreme the environment is can we still complete the exploitation to the vulnerabilities? Can we develop a universal exploitation that is not just the ideal one in lab environment but the powerful one that can be applied to the real-world vulnerabilities?
Google has shown us how to turn a 2-byte heap-out-of-bound vulnerability into a universal solution in CVE-2021-22555. BitsByWill demonstrated the powerful page-level heap Feng Shui that can break the isolation between kmem_cache in corCTF2022 . D3v17 archive the privilege escalation with only a single null-byte heap overflow vulnerability using the poll_list, and Kylebot converted it into a cross-cache overflow exploit using the unlinking attack. So, what’s next?
- If the size of the struct where the vulnerability located is not appropriate, or the struct itself cannot help us exploit the vulnerability, we have to use struct like
msg_msgto adapt. But such kernel struct is rare with many limitations in exploit(e.g. they’re usually with a troublesome header). - If the vulnerability exists in a standalone
kmem_cache, we cannot exploit it with other struct’s help directly. The cross-cache overflow may be the only way to achive. - If we get only 1-byte overflow in vulnerability, or the system V IPC is banned, we cannot apply Google’s solution to construct a use-after-free.
- If the memory is small, or the variables like
modprobe_pathis a static value, Kylebot’s unlink attack is no longer available. - Though the D3v17’s
poll_listmay still be available, the first-levelpoll_listis always in order-3 pages. If the vulnerability located in other-size slab (e.g. order-0 pages), we must resort to more granular page-level heap Feng Shui, where inter-order Feng Shui will greatly reduce the success rate. - If the kernel has Control Flow Integrity enabled, or if we don’t even know the kernel image information, traditional ROP methods are essentially dead.
In such extreme conditions, can we still find a universal solution to exploit kernel vulnerabilities? This was my original idea when creating this challenge. :)
0x01.Analysis
There’s no doubt that it’s easy to reverse the kernel module I provided. It create an isolate kmem_cache that can allocate objects in size 2048.
1 |
|
The custom d3kcache_ioctl() function provides a menu for allocating, appending, freeing, and reading objects from kcache_jar , and the vulnerability is just in appending data, where there is a null-byte buffer overflow when writing surpasses 2048 bytes.
1 | long d3kcache_ioctl(struct file *__file, unsigned int cmd, unsigned long param) |
We can also find that the Control Flow Integrity is enabled while checking the config file provided.
1 | CONFIG_CFI_CLANG=y |
0x02. Exploitation
As the kmem_cache is an isolate one, we cannot allocate other regular kernel structs from it, so the cross-cache overflow is the only solution at the very beginning.
Step.I - Use page-level heap Feng Shui to construct a stable cross-cache overflow.
To ensure stability of the overflow, we use the page-level heap Feng Shui there to construct a overflow layout.
How it works
Page-level heap Feng Shui is a technique that is not really new, but rather a somewhat new utilization technique. As the name suggests, page-level heap Feng Shui is the memory re-arrangement technique with the granularity of memory pages. The current layout of memory pages in kernel is not only unknown to us but also has a huge amount of information, so the technique is to construct a new known and controlable page-level granularity memory page layout manually.
How can we achieve that? Let’s rethink about the process how the slub allocator requests pages from buddy system. When the slab pages it use as the freelist has run out and the partial list of kmem_cache_node is empty, or it’s the first time to allocate, the slub allocator will request pages from buddy system.
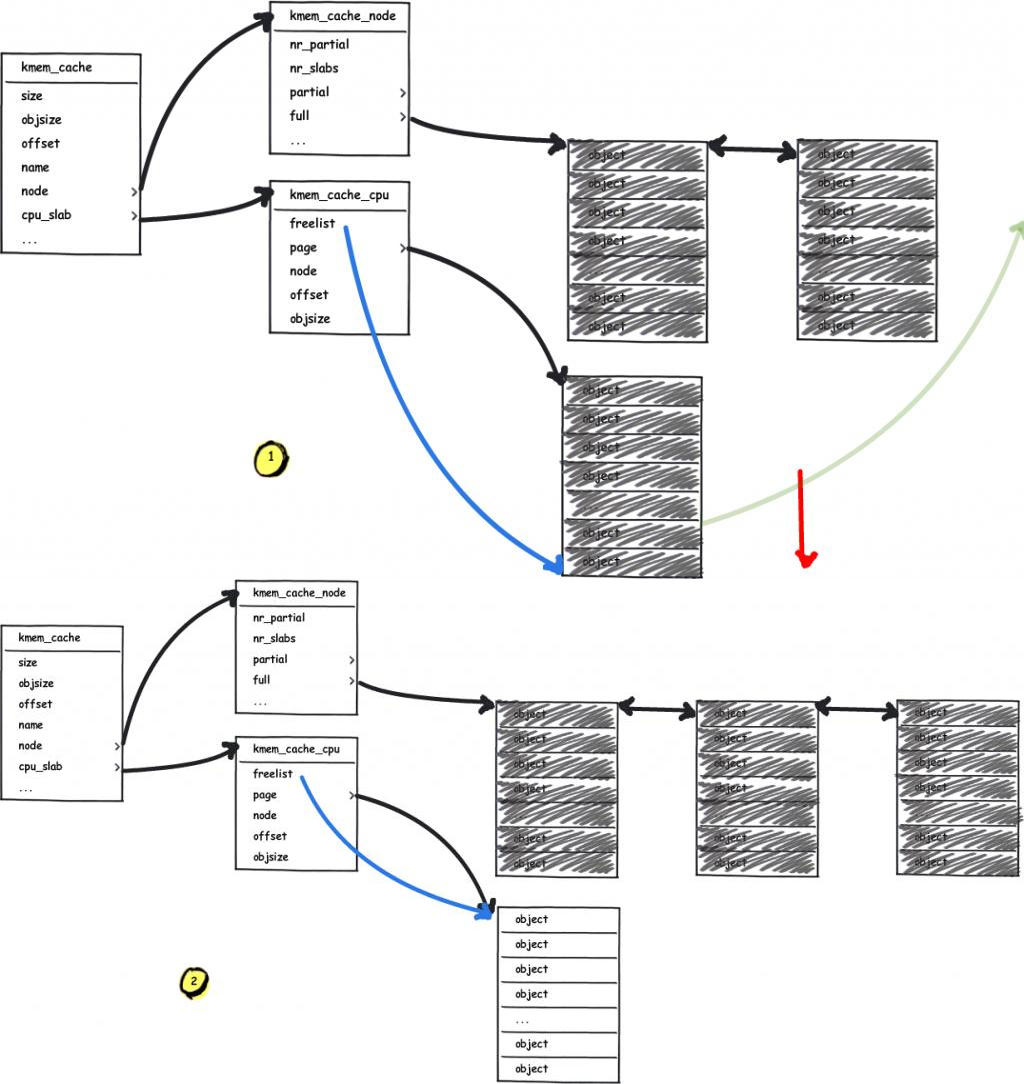
The next one we need to rethink about is how the buddy system allocates pages. It takes the 2^order memory pages as the granularity of allocation and the free pages in different order are in different linked lists. While the list of allocated order cannot provide the free pages, the one from list of higher order will be divided into two parts: one for the caller and the other return to corresponding list. The following figure shows how the buddy system works actually.
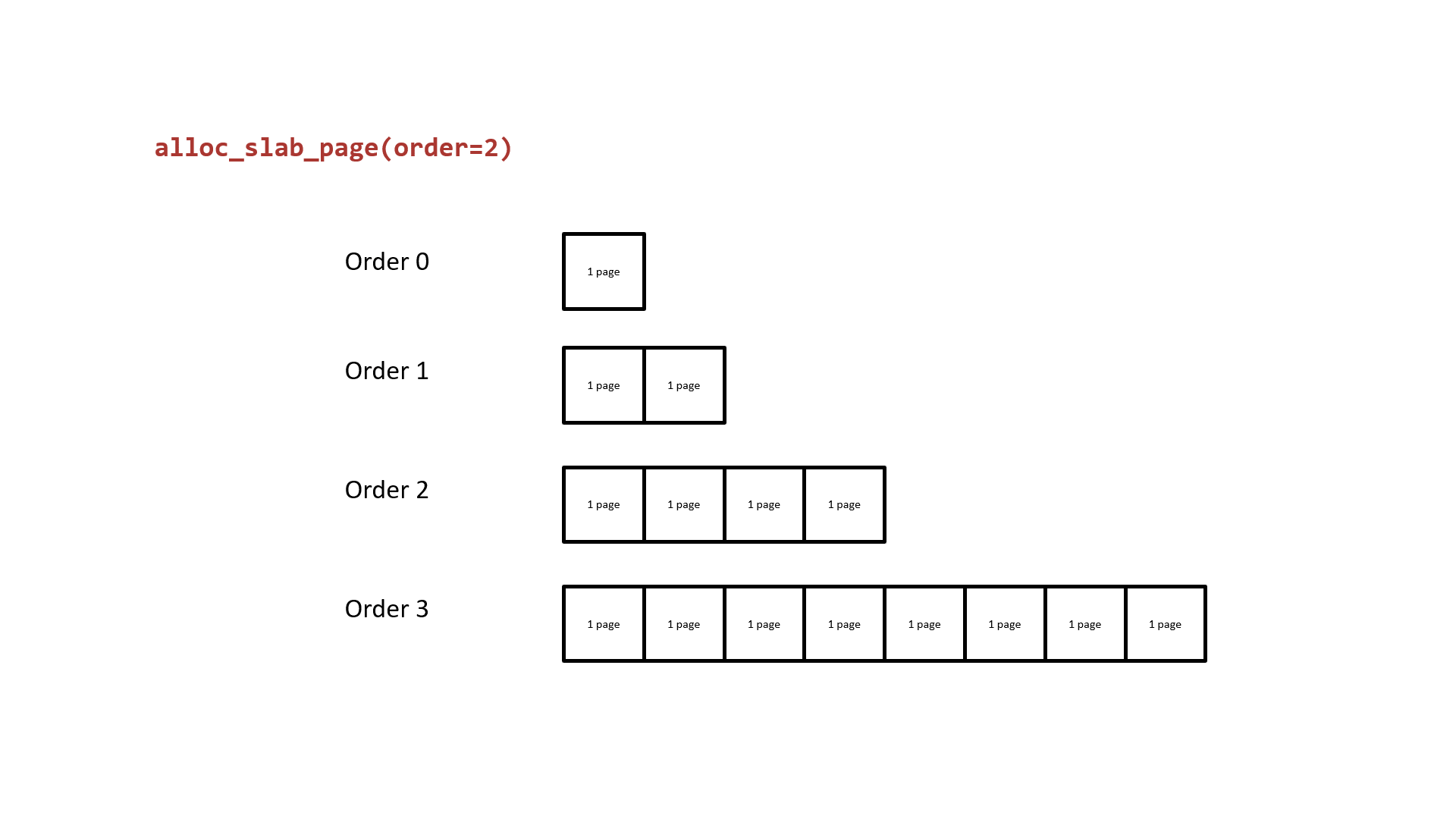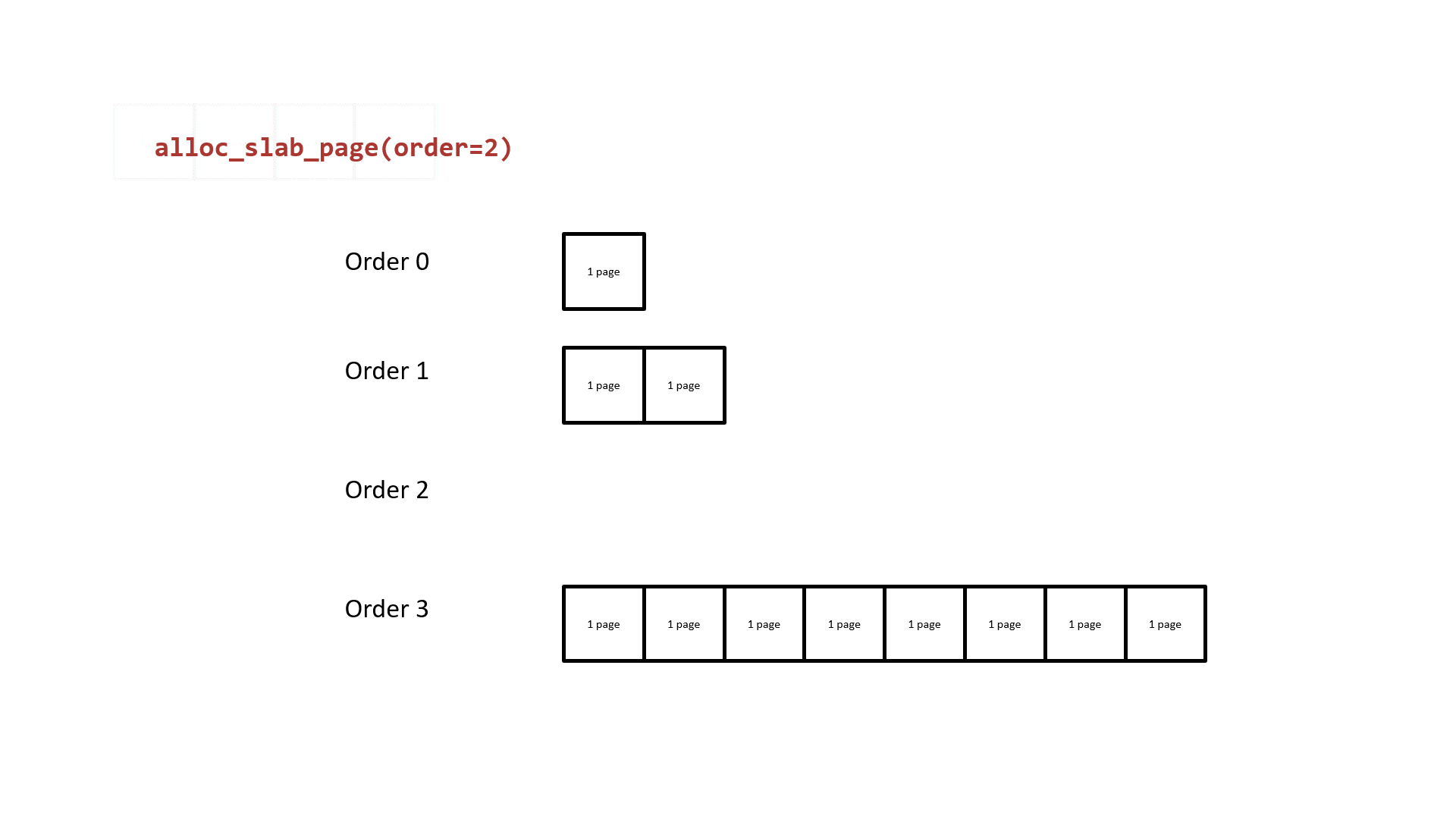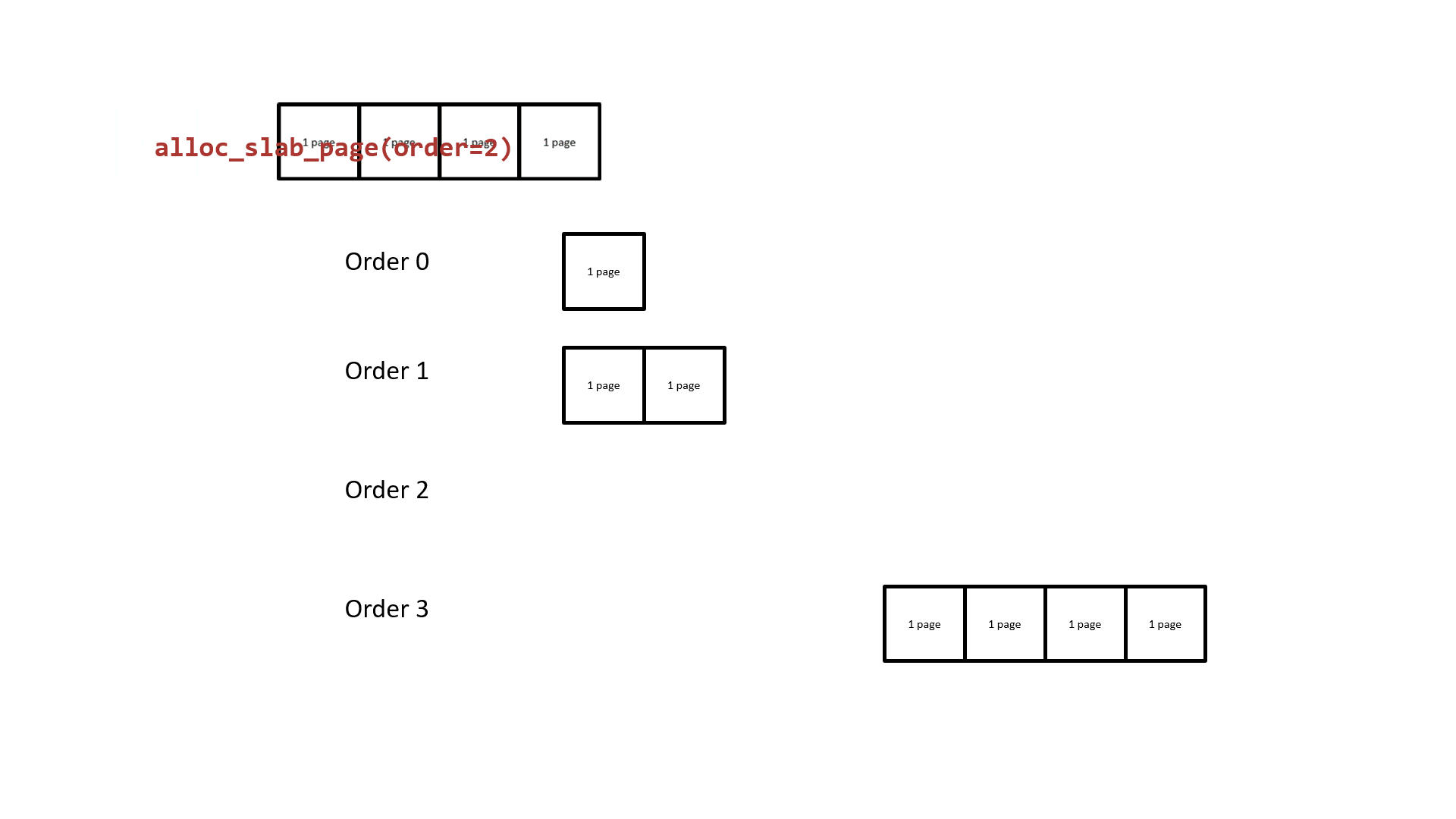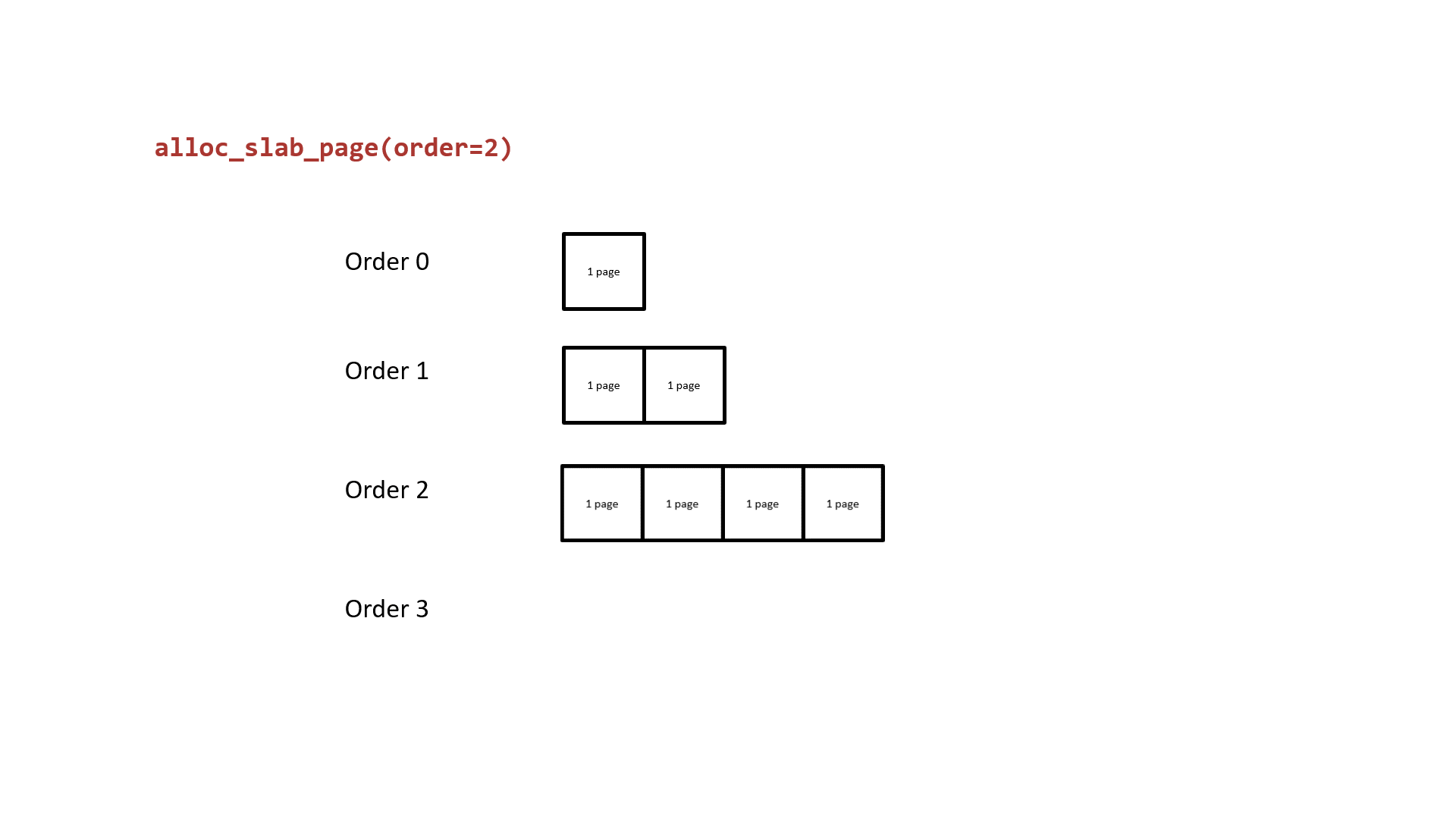
Notice that the two low-order continuous memory pages obtained by splitting them from a higher-order are physically contiguous. Thus, we can:
- Request two continuous memory pages from the buddy system.v
- Release one of the memory pages, do the heap spraying on vulnerable
kmem_cache, which will make it take away this memory pages. - Release the other memory page, do the heap spraying on victim
kmem_cache, which will make it take away this memory pages.
Now the vulnerable and victim kmem_cache both hold the memory pages that are near by each other’s one, which allow us to achive the cross-cache overflow.
How we exploit
There’re many kernel APIs that can request pages directly from the buddy system. Here we’ll use the solution from CVE-2017-7308.
When we create a socket with the PF_PACKET protocol, call the setsockopt() to set the PACKET_VERSION as TPACKET_V1 / TPACKET_V2 , and hand in a PACKET_TX_RING by setsockopt() , there is a call chain like this:
1 | __sys_setsockopt() |
A pgv struct will be allocated to allocate tp_block_nr parts of 2^order memory pages, where the order is determined by tp_block_size:
1 | static struct pgv *alloc_pg_vec(struct tpacket_req *req, int order) |
The alloc_one_pg_vec_page() will call the __get_free_pages() to request pages from buddy system, which allow us to acquire tons of pages in different order:
1 | static char *alloc_one_pg_vec_page(unsigned long order) |
Correspondingly the pages in pgv will be released after the socket is closed.
1 | packet_release() |
Such features in setsockopt() allow us to achieve the page-level heap Feng Shui. Note that we should avoid those noisy objects (additional memory allocation) corruptting our page-level heap layout. Thus what we should do is to pre-allocate some pages before we allocate the pages for page-level heap Feng Shui. As the buddy system is a LIFO pool, we can free these pre-allocated pages when the slab is being running out.
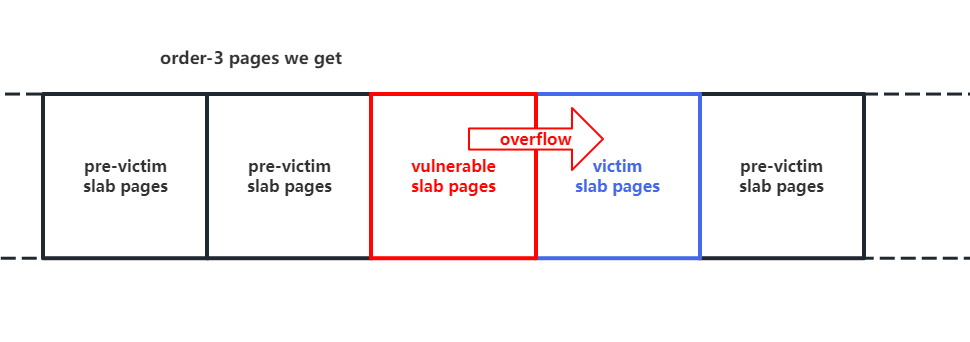
Thus, we can obtain the page-level control over a continuous block of memory, which allow us to construct a special memory layout within follow steps:
- First, release a portion of the pages so that the victim object obtains these pages.
- Then, release a block of pages and do the allocation on the kernel module, making it request this block from the buddy system.
- Finally, release another portion of the pages so that the victim object obtains these pages.
As a result, the vulnerable slab pages will be around with the victim objects’ slab pages as the figure shown, which ensure the stablity of cross-cache overflow.
Step.II - Use fcntl(F_SETPIPE_SZ) to extend pipe_buffer, construct page-level UAF
Now let’s consider the victim object as the target of cross-cache overflow. I believe that the powerful msg_msg is the first one that comes to everyone’s mind. But we’ve use msg_msg for too many times in the past exploitation on many vulnerabilities. So I’d like to explore somthing new this time. : )

Due to the only one-byte overflow, there’s no doubt that we should find those structs with pointers pointing to some other kernel objects in their header. The pipe_buffer is such a good boy with a pointer pointing to a struct page at the beginning of it. What’s more is that the size of struct page is only 0x40, and a null-byte overflow can set a byte to \x00, which means that we can make a pipe_buffer point to another page with a 75% probability.
So if we spray pipe_buffer and do the null-byte cross-cache overflow on it, there’s a high probability to make two pipe_buffer point to the same struct page. When we release one of them, we’ll get a page-level use-after-free. It’s as shown in following figures.
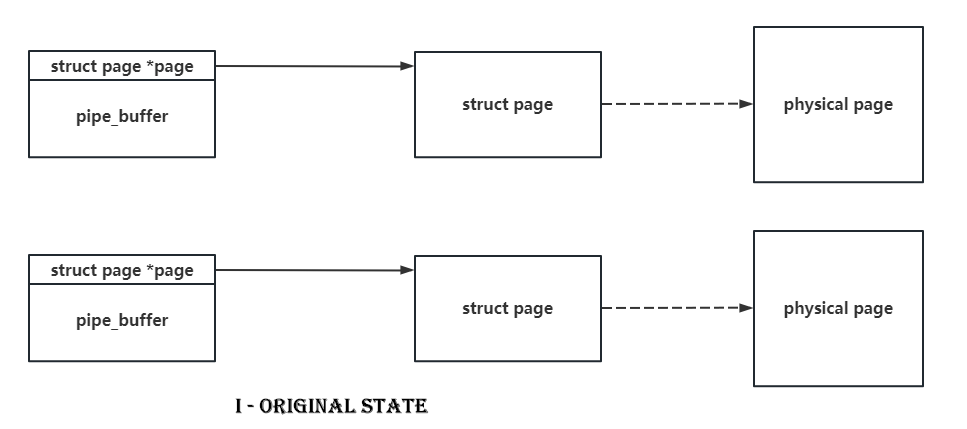
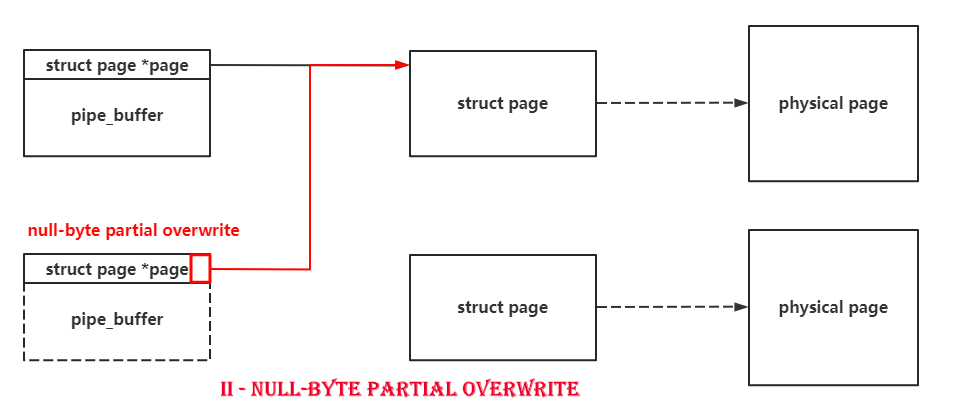
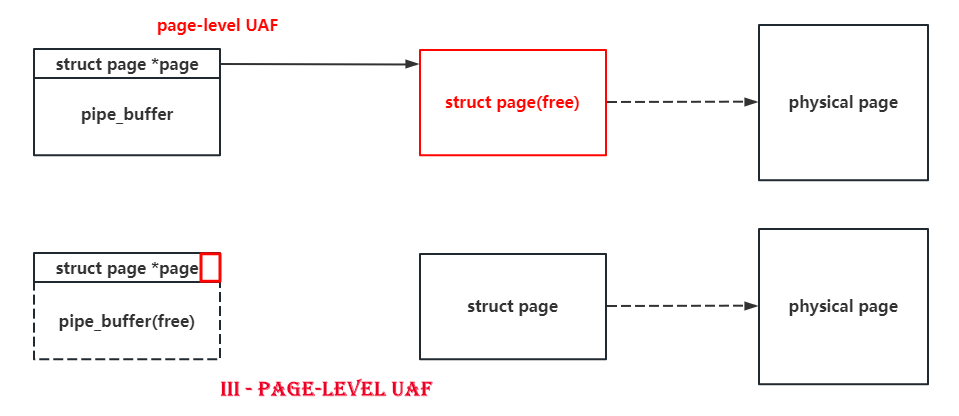
What’s more is that the function of pipe itself allow us to read and write this UAF page. I don’t know whether there’s another good boy can do the same as the pipe does : )
But there’s another problem, the pipe_buffer comes from the kmalloc-cg-1k pool, which requests order-2 pages, and the vulnerable kernel module requests the order-3 ones. If we perform the heap Feng Shui between dirfferent order directly, the success rate of the exploit will be greatly reduced :(
Luckily the pipe is much more powerful than I’ve ever imagined. We’ve known that the pipe_buffer we said is actually an array of struct pipe_buffer and the number of it is pipe_bufs .
1 | struct pipe_inode_info *alloc_pipe_info(void) |
Note that the number of struct pipe_buffer is not a constant, we may come up with a question: can we resize the number of pipe_buffer in the array? The answer is yes. We can use fcntl(F_SETPIPE_SZ) to acjust the number of pipe_buffer in the array, which is a re-allocation in fact.
1 | long pipe_fcntl(struct file *file, unsigned int cmd, unsigned long arg) |
Thus, we can easily reallocate the number of pipe_buffer to do a re-allocation: for each pipe, we’d like to allocate 64 pipe_buffer, making it request an order-3 page from kmalloc-cg-2k, which is the same order as the vulnerable kernel module. So that the cross-cache overflow is in a high reliability.
Note that the size of struct page is 0x40, which means that the last byte of a pointer pointing to it can be \x00. If we make a cross-cache overflow on such pipe_buffer, it’s equal to nothing happen. So the actual rate of a successful exploitation is only 75% : (
Step.III - Construct self-writing pipes to achive the arbitrary read & write
As the pipe itself provide us with the ability to do the read and write to specific page, and the size of pipe_buffer array can be control by us, it couldn’t be better to choose the pipe_buffer as the victim object again on the UAF page : )
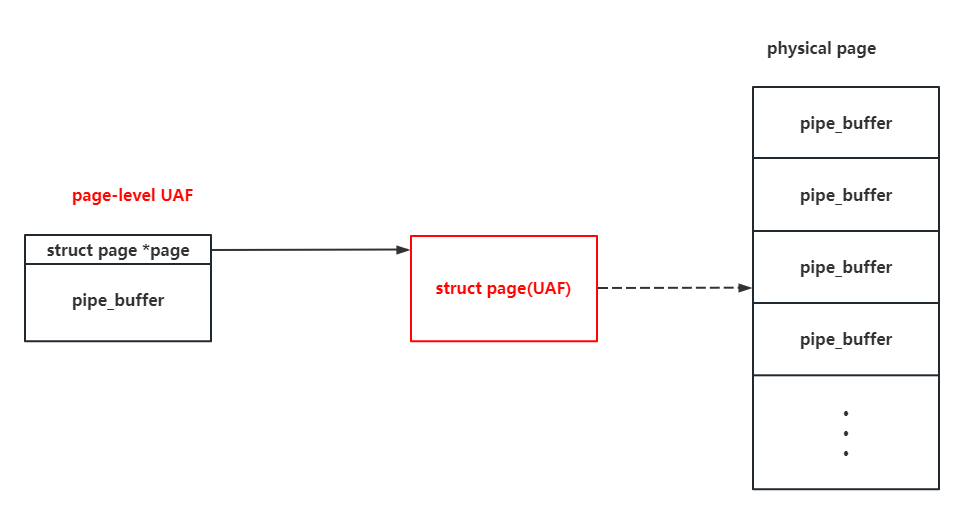
As the pipe_buffer on the UAF page can be read & write by us, we can just simply apply the pipe primitive to perform the dirty pipe (That’s also how the NU1L team did to solve it).
But as the pipe_buffer on the UAF page can be read & write by us, why shouldn’t we construct a second-level page-level UAF like this?
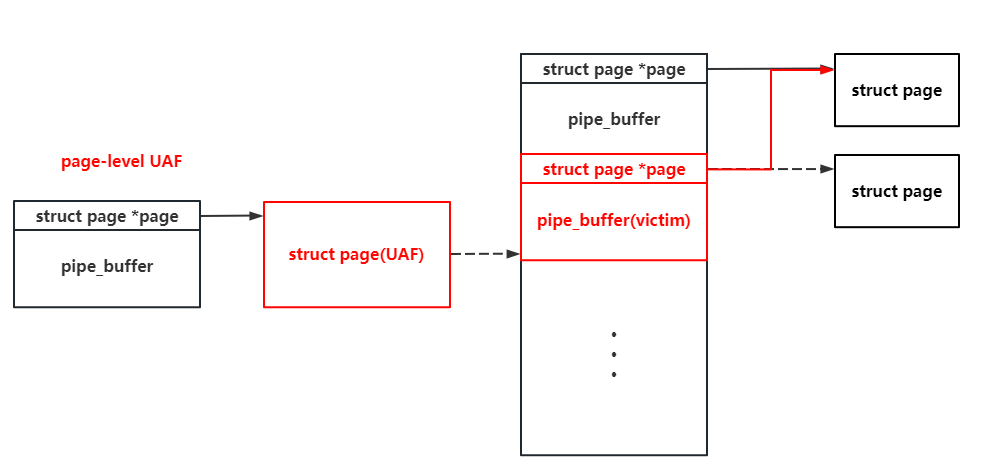
Why? The page struct comes from a continuous array in fact, and each of them is related to a physical page. If we can tamper with a pipe_buffer ‘s pointer to the struct page, we can perform the arbitrary read and write in the whole memory space. I’ll show you how to do it now : )
As the address of one page struct can be read by the UAF pipe (we can write some bytes before the exploitatino starts), we can easily overwrite another pipe_buffer ‘s pointer to this page to. We call it as the second-level UAF page. Then we close one of the pipe to free the page, spray the pipe_buffer on this page again. As the address of this page is known to us, we can tamper with the pipe_buffer on the page pointing to the page ie located directly, which allow the pipe_buffer on the second-level UAF page to tamper with itself.
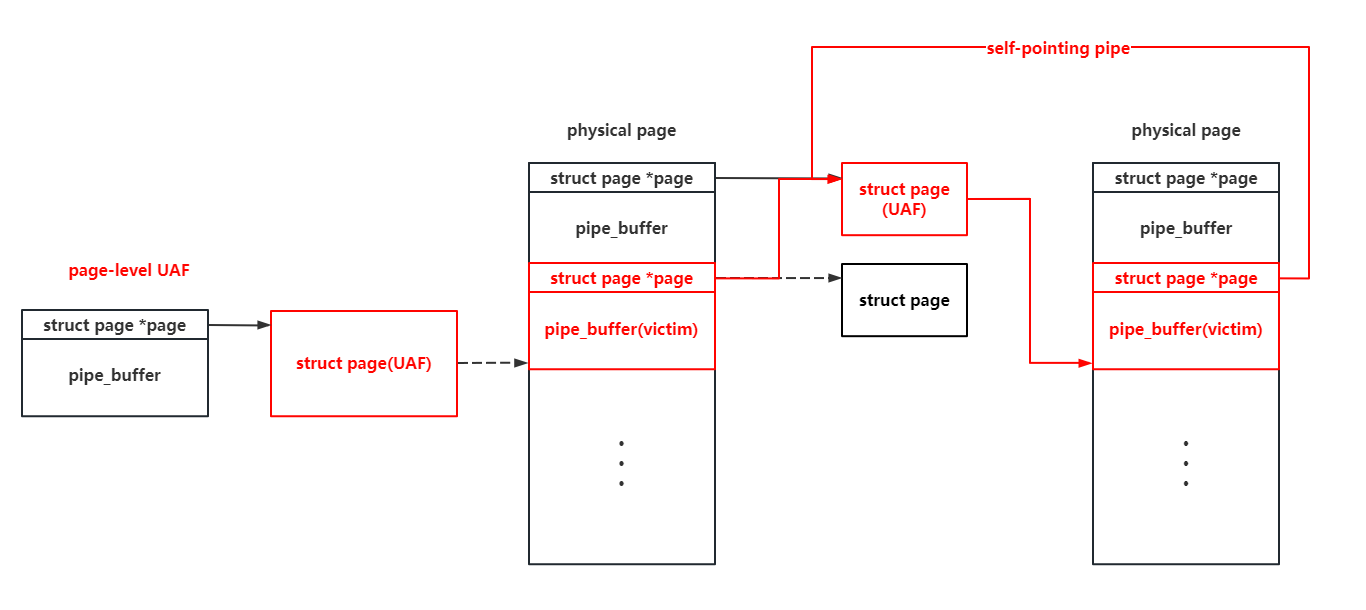
We can tamper with pipe_buffer.offset and pipe_buffer.len there to relocate the start point of a pipe’s read and write, but these variables will be reassigned after the read & write operation. So we use three such self-pointing pipe there to perform an infinite loop:
- The first pipe is used to do the arbitrary read and write in memory space by tampering with its pointer to the
pagestruct. - The second pipe is used to change the start point of the third pipe, so that the third pipe cam tamper with the first and the second pipe.
- The third pipe is used to tamper with the first and the second pipe, so that the first pipe can read & write arbitrary physical page, and the second pipe can be used to tamper with the third pipe.
With three self-pointing pipe like that, we can perform infinite arbitrary read and write in the whole memory space : )
Step.IV - Privilege escalation
With the ability to do the infinite arbitrary read and write in the whole memory space, we can escalate the privilege in many different ways. Here i’ll give out three meothds to do so.
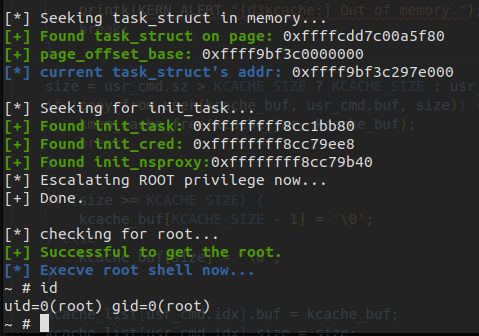
Method 1. Change the cred of current task_struct to init_cred
The init_cred is the cred with root privilege. If we can change current process’s task_struct.cred to it, we can obtain the root privilege. We can simply change the task_struct.comm by prctl(PR_SET_NAME, "arttnba3pwnn"); and search for the task_struct by the arbitrary read directly.
Sometimes the init_cred is not exported in /proc/kallsyms and the base address of it is hard for us to get while debugging. Luckily all the tasj_struct forms a tree and we can easily find the init ‘s task_struct along the tree and get the address of init_cred .
Methord 2. Read the page table to resolve the physical address of kernel stack , write the kernel stack directly to perform the ROP
Though the CFI is enabled, we can still perform the code execution. As the address of current process’s page table can be obtained from the mm_struct, and the address of mm_struct and kernel stack can be obtained from the task_struct , we can easily resolve out the physical address of kernel stack and get the corresponding page struct. Thus we can write the ROP gadget directly on pipe_write() ‘s stack.
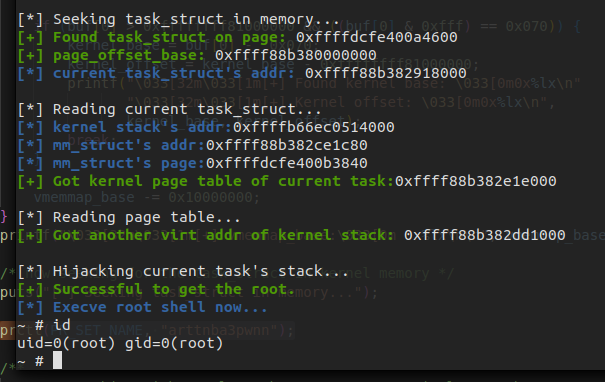
But this solution is not always available. Sometimes the control flow won’t be hijacked after the ROP gadgets are written into the kernel stack page. I don’t know the reason why it happened yet : (
Method 3. Read the page table to resolve the physical address of kernel code, map it to the user space to overwrite the kernel code(USMA)
It may also be a good way to overwrite the kernel code segment to perform the arbitrary code execution, but the pipe actually writes a page by the direct mapping area, where the kernel code area is read-only.
But what we want to do in fact is to write the corresponding physical page, and the page table is writable. So we can simply tamper with the page table to establish a new mapping to kernel code’s physical pages : )
This is actually the same way as the USMA does.
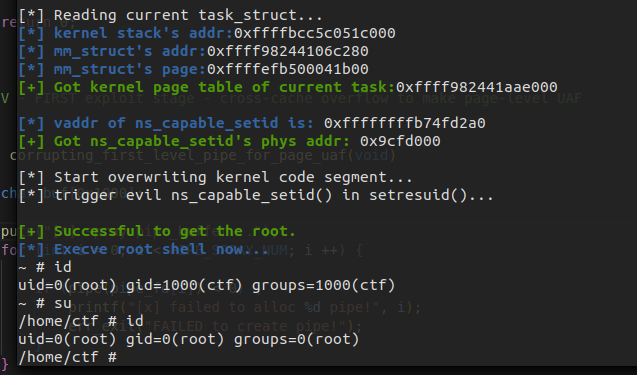
Final Exploitation
Here is the final code for the explotation with three different ways to obtain the root privilege. The totabl reliability is about 75%.
1 |
|
0x03. Conclusion
My d3kcache challenge has only two solvers this time: NU1L and TeamGoulash. Both teams chose to overwrite the busybox to obtained the flag.
NU1L team sprayed the msg_msg and used this null-byte overflow to do a partial overwrite on the msg_msg->m_list.next to construct a UAF (similar to CVE-2021-22555). Then they sprayed the msg_msgseg to construct a fake msg_msg, overwrite the m_ts to perform the out-of-bound read. Finally they used fcntl(F_SETPIPE_SZ) to resize the pipe_buffer to fit in the UAF object, using pipe primitive to perform the dirty pipe attack. As the msg_msg in size 0x1000 also come from order-3, it’s also possible for them to achieve the corss-cache overflow. But at the first stage they need to fit in a pipe_buffer with the size of 0xc0 (from kmalloc-cg-192), the total reliability is about 1/16.
TeamGoulash used the fcntl(F_SETPIPE_SZ) to let the pipe_buffer fit in order-3 to do a page-level UAF. Then they fork() a new process out to try to re-allocate the UAF page as the part of its page table. As the page table is writable, they mapped the read-only busybox into the memory and make it writable to perform a write beyond privilege. However there’re so many noisy objects that may get this UAF page, the total reliability is about 5%.
Generally speaking, I’m satisfied with my d3kcache challenge. Hope that I can bring you something more interesting in the future : )
